SugarCRM deployment process
Aug 26, 2018 · 11 min readSugarCRM is a Customer Relationship Management system for both Enterprise and small business. I’ve worked on SugarCRM for around 6 years, and this post is going to cover off how we release/deploy the software on a 2 week cycle.
The Aim
As with any software, the aim is to have an automated release process first and foremost. We wanted this process to be simple and allow for a completely automated release to our staging platform on a nightly basis. We wanted the release to the production platform to have some manual intervention so there was ownership and accountability.
It should be: Easy; A click of a button; Monitored
Although we have a release schedule of every 2 weeks, we also wanted to be able to release instantly for hot fixes, should the need arise.
Flow
We wanted a flow that pushed up through our platforms, starting from a developers’ virtual machine, then to staging, then to production. This means you cut all the deployment bugs down, as we have to uplift the release candidate to the relevant platform, proving we can release to production. There should be no manual steps to the staging platform, as this could be missed when we deploy to production.
Tools
In order to achieve our automated release pipeline, we use the following tools
Makefile
Makefiles are pervasive in our software. It’s the default build tool, irrelevant of the underlying language being used. Each time we onboard a developer into our team, the first thing they do is checkout the git repo, and run $ make
$ make
### Welcome
#
# Makefile for the SugarCRM application
#
### Installation
#
# New repo from scratch?
# -> $ make clean install
#
### ....
### [more explanations and documentation to developers]
### ....
#
### Targets
#
check-release Check to see if the release can happen
clean Clean the local filesystem
deploy-holding-off Take the holding pages down
deploy-holding-on Deploy the holding pages (config/deployment.tmp has the details you may want to change)
deploy-hotfix Deploy a "hotfix" from a git commit to a specific platform
deploy Create and deploy the tarballs
install-vendors Install all the vendors we need (Differs when run on vagrant and host)
install Install the application
promote Promote a release candidate to being "live"
release-complete Commit all changes, branches and tags back to Git
release-create Create the release locally ready for git commit
release Release the tarballs. Expected to be run on the live platform via another application (e.g Jenkins)
### ....
## [cut down to release specific targets]
### ....In relation to the release process, the Makefile documents how to clean the local area, install dependencies, package the software, install the software, understand how to do any auxiliary work like running a “Repair and Rebuild” in SugarCRM.
It does not understand the topology of the target platform.
Bash Scripts
We have a deploy.sh script that co-ordinates all of the deployment activities into one place. This historically was in Jenkins, however, changes to the release process seemed to be stuck with one or two individuals who maintained Jenkins. The aim of moving this into the git repo of the application is to create a sense of ownership. The file is right there in OUR repo, WE own it, WE change it, WE love it 💚
This script is responsible for tying all the release items up together, and covers:
- Turn the crontab off - This is important because we are trying to reduce load on the SugarCRM application. During a release you have to run “Repair and Rebuild”, and SugarCRM gets very upset when the system is under load
- Clean the local build directories
- Install all the dependencies - We have our own
composer.jsonfile above and beyond what SugarCRM provide. We also have a Symfony application integrated into SugarCRM. So this process covers all the dependencies we have - Deploying the tarball to the relevant platforms - This does not impact the live application, as it’s simply a deployment mechanism. We store a config file for each platform, so the deployment process identifies the target platform and copies the relevant configuration files for SugarCRM, Cron and Symfony
- Promotion of the release - This is where we start to impact the running of the application, because of the way SugarCRM’s caching system works. When running “Repair and Rebuild” it impacts the filesystem and the database, therefore you cannot prime the environment and simply switch the symlink, you have a couple of minutes of down time whilst the cache is warmed
- Turn the crontab on - Now the promotion has happened, we can turn the crontab back on
- Rebooting of Apache for all the servers - This clears the Opcache, and is done one at a time so there is always web servers active
- If we are deploying to production we merge the release into
masterand create all the necessary tags in git etc, and push back to GitHub - We ping Grafana to notify that a release has taken place
This script is fairly basic in the logic used and outputs clean section headers for each step etc. It also has some sanity checks in there to make sure we are not doing something we will later regret. Some of the above should be self explanatory, but the interesting items are discussed below
Promotion
release: check-release ## Release the tarballs. Expected to be run on the live platform via another application (e.g Jenkins)
# Symfony cache:clear
subdomains/app/bin/console --env=prod cache:clear --no-warmup
subdomains/app/bin/console --env=dev cache:clear --no-warmup
# Symfony assets:install
subdomains/app/bin/console --env=prod assets:install subdomains/app/web/
subdomains/app/bin/console --env=dev assets:install subdomains/app/web/
# Executing Pre Release Scripts
bin/cli.php crm:run-release-scripts --type=pre --branch=$(BRANCH) --folder=$(RELEASE_FOLDER)
# Running automated repair and rebuild
bin/cli.php sugar:repair-rebuild
# Running automated repair and rebuild (again)
bin/cli.php sugar:repair-rebuild
# Running automated rebuild relationships
bin/cli.php sugar:rebuild-relationships
promote: ## Promote a release candidate to being "live"
# Executing Post Release Scripts
bin/cli.php crm:run-release-scripts --type=post --branch=$(BRANCH) --folder=$(RELEASE_FOLDER)
# Copy the platform SugarCRM Config over
cp config/config.php.$(PLATFORM) src/config.php
# Link us into the live folder
rm -fr /path/to/app/sugarcrm && ln -s /path/to/app/sugarcrm-$(RELEASE_VERSION) /path/to/app/sugarcrm
# Installing new crontab scripts/cron/crontab-master
crontab scripts/cron/crontab-master
We have built our own Symfony CLI application, which wraps some of the SugarCRM administration, to make our operational tasks easier. This is similar to the bin/sugarcrm application which has subsequently been released in the core product.
We have found that it is necessary sometimes to run the “Repair and Rebuild” process a couple of times, so this is now the standard. We do not really want to fire up the SugarCRM administration UI either, so we have automated the rebuilding of relationships too, in case anything has changed in the sprint.
The other section of interest is we have a Symfony command that automates some of the release scripts we may need to run. This can be run in pre or post mode, which enables us to automate the running of Bash, PHP or SQL scripts in a given order before and after the “Repair and Rebuild”.
Notifying Grafana
.PHONY: notify-grafana ## Send a release marker to Grafana
notify-grafana:
curl -H "Authorization: Bearer [Token]" \
-X POST \
-H "Content-Type: application/json" \
-d '{"tags":["release","release-sugarcrm”,”release-sugarcrm-$(RELEASE_VERSION)"], "text”:”SugarCRM Release $(RELEASE_VERSION)"}' \
"http://grafana.instance.url:8080/api/annotations"
As mentioned at the start, we wanted our releases to be monitored, so we ping Grafana to notify a release has taken place.
Jenkins
Jenkins is the UI mechanism we interact with to deploy our software. It checks out the application from GitHub, and then runs deploy.sh. It asks the developer: Which branch to release; whether to bounce apache, and whether to do all the version control work.
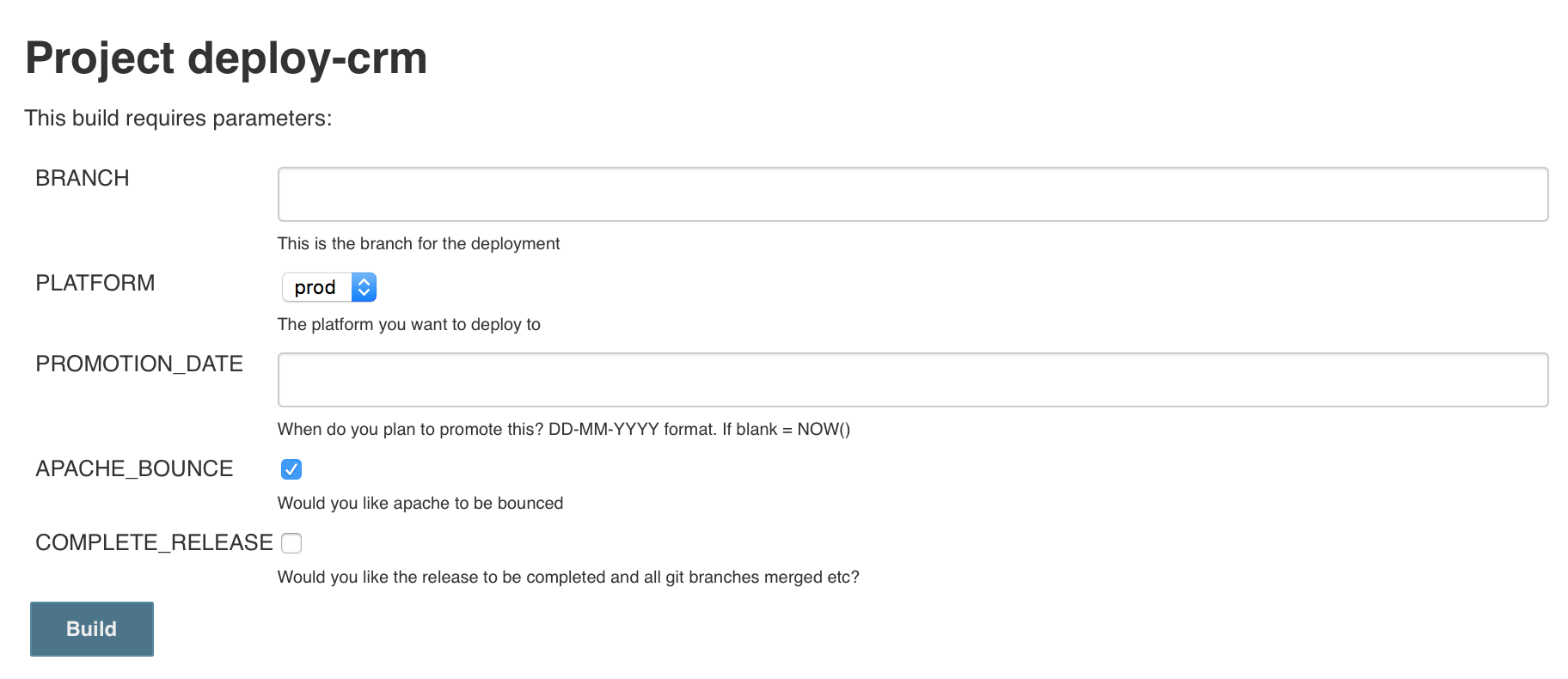
You could deploy from a developers’ machine if you wished, but Jenkins gives a nice UI and is globally available to us. It’s a nice tool to be able to provide read access to other people who may want to know when a release is finished. Jenkins also posts into our Slack channels, so folks know if a deployment was successful or not. It’s also clean, in the sense that you know what is on the platform (nothing). If you did this on a developers machine, although we check and clean the local environment, it just seems riskier to me.
Monitoring
Releases are risky business.
However, if you have an automated release which is tested, constantly, the risk is lowered. If you have enough telemetry to know if a release is good or bad, the risk is lowered. Telemetry is the lifeblood of a release. Without it, I don’t know how you gain the courage to release. If I couldn’t see error rates, or traffic, or CPU usage, or memory usage, or feature usage, I would be horrified releasing software.
When we deploy SugarCRM, we are looking for
- 412 HTTP Response codes. This is what happens when you clear and generate a new cache (From “Repair and Rebuild”). You will see a big spike in these responses before the system calms down after a release
- Successful SugarCRM logins
- The average API response time (All the calls running through
api/rest.php) - Overall traffic to the site (Have we broken apache for example)
- Database connections, CPU, Memory
- The health of the applications that integrate into SugarCRM. We have 2 other applications that are heavily integrated into the SugarCRM application, and luckily it’s all monitored in Grafana so we can see if they are “healthy” too after a release
We are generally monitoring the software on any given day, but rely more on Slack notifications for any issues we need to immediately focus on. However, during a release we are more hands on, actively looking through the hundreds of graphs and dashboards we have built over the years. After a while, you naturally know what the system should “look like” at any given time (9am, lunchtime, a release, bank holidays etc). This makes it much easier to understand issues when the graphs deviate from what is “normal”. We know, for example, that we will see Apache Segfaults and Apache Bus Errors (Seems to be NFS related, a long, long story) during the Repair and Rebuild process! We know we will see the spike in 412 HTTP response codes and the average API time will increase for about 15 to 20 minutes before it calms down again.
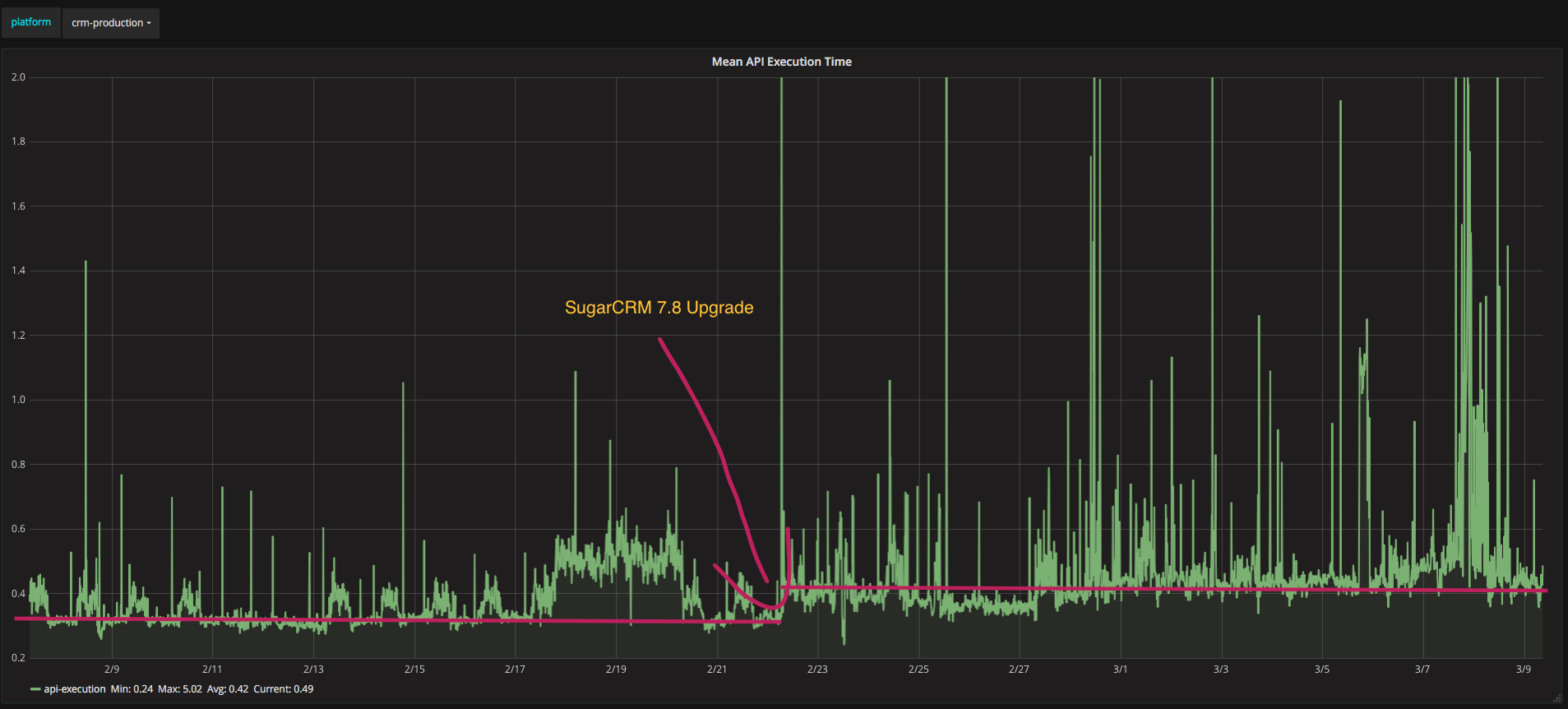
And of course, with rich telemetry you can zoom out and see historical trends. For example we knew that for our installation, with our customisations, SugarCRM 7.8 was slightly less performant than SugarCRM 7.7. It is vital you have this kind of telemetry to understand the systems you build.
What does it mean as a SugarCRM administrator to release this way
As with anything, there is a trade off. In order to have a very slick flow from development to production, and for it all to be version controlled, administrators lose some tools.
One such tool is “Studio”. This enables administrators/product owners to add/remove/edit fields, relationships, change views etc. However, if we let them do this, because of the way SugarCRM splits the cache between the filesystem and the database, developers would not get these changes, nor would they be version controlled. For an enterprise solution, there are more benefits than negatives by taking this away from administrators. It is more beneficial to have clear ownership and version controlled software, which is easily deployed via an automated procedure.
Another area that is slightly more awkward than you would hope is a SugarCRM upgrade. A SugarCRM upgrade can be done in the UI or the CLI. I have never done one in the UI, so cannot comment. However, the CLI documentation generally hints at you running this on production, after running it on your staging platform to confirm it works. Again, this would mean nothing is version controlled, which is scary. Or, would rely on developers coping all the files down from production, again, scary. So, we run the upgrade on a development machine, commit all the changes, and then pull down onto a secondary machine to see if we have upgraded correctly. Then we build a SQL script to replay the database changes the CLI upgrade script has completed for us. It’s not great. Ideally, I would like to see SugarCRM become a vendor in the composer.json file, so that easily sorts the code out. Then if the CLI application could be broken down into logical sections such as schema changes, data cleanup etc, they could be run on each platform.
Lastly, the area that has caused us some grief, so worth calling out, is Enums (Drop down list items). Enums seem to upset people the most, the fact that they cannot just change an Enum themselves in the administration area as documented here. Why can they not do this? The tool makes code changes to files that need to be version controlled. So, Enums need to be controlled by development and uplifted to the relevant platforms as per the release process. It would be very good if SugarCRM built a database solution for this, as this would also help Data Warehouse solutions, which want to know what the value is for the key stored (In any language they pick).
The end
Hopefully this covers off how we have been successfully releasing SugarCRM every two weeks, without fail, for over 5 years. Whether it’s a small release from the Holiday season, or a massive SugarCRM upgrade (Looking at you SugarCRM 7.9 with your full re-write of the Quotes module 🤯), the automation and monitoring put in place makes these releases no different.